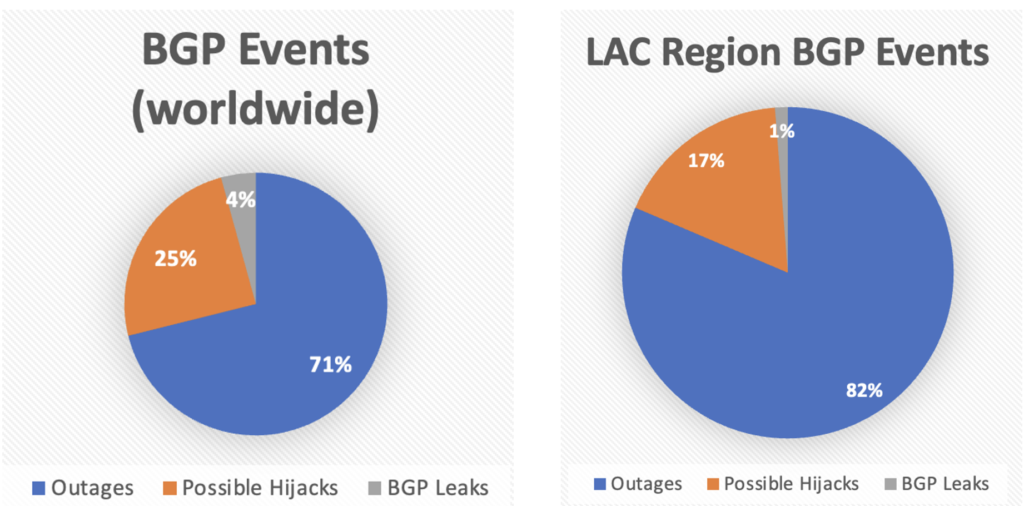
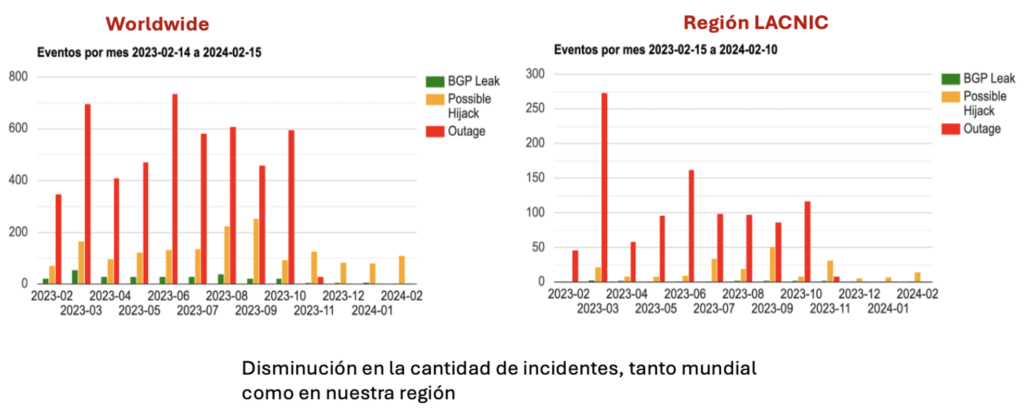
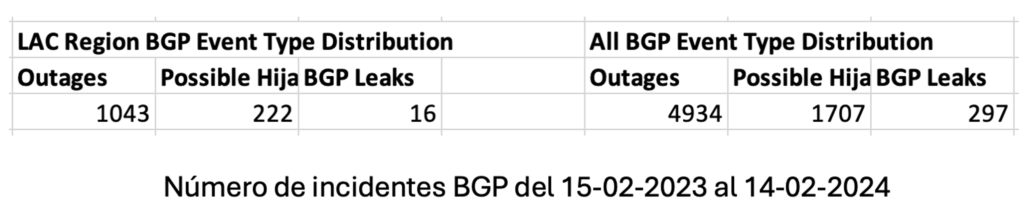
A route leak is defined as the propagation of routing announcement(s) beyond their intended scope (RFC 7908). But why do route leaks occur? The reasons are varied and include errors (typos when entering a number), ignorance, lack of filters, social engineering, and others.
Although there are several ways to prevent route leaks and, in fact, their number has decreased over the past three years (thanks to RPKI, IRR, and other mechanisms), I will try to explain what I believe BGP configurations will look like in the future. To do so, I will talk about RFC 9234, Route Leak Prevention and Detection Using Roles in UPDATE and OPEN Messages. And the part I would like to highlight is “role detection” as, after this RFC, in the future, we will assign roles in our BGP configurations.
To understand what we want to achieve, let’s recall some typical situations for an ISP:
a new customer comes along with whom we will speak BGP,
a connection to an IXP,
the ISP buys capacity from a new upstream provider,
a new private peering agreement.
In all these cases decisions need to be made. There are multiple ways to configure BGP, including route maps, AS filters, prefix lists, communities, ACLS, and others. We may even be using more than one of these options.
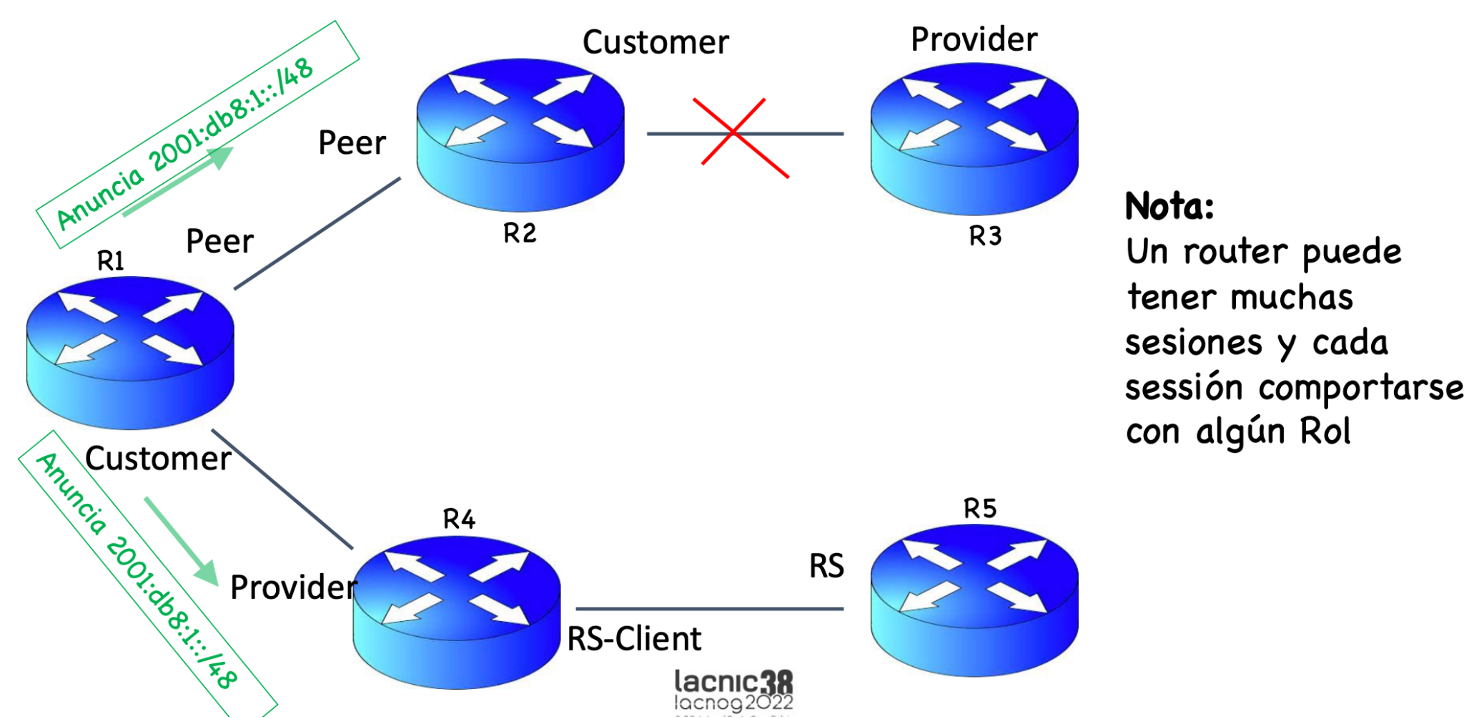
This is where RFC 9324 enters the picture: the document establishes the roles in the BGP OPEN message, i.e., it establishes an agreement of the relationship on each BGP session between autonomous systems. For example, let’s say that I am a router and I speak to another router and tell them that I am a “customer”; in turn, the other router’s BGP session can say “I am your provider.” Based on this exchange, all configurations (i.e., filters) will be automatic, which should help reduce route leaks.
These capabilities are then negotiated in the BGP OPEN message.
The RFC defines five roles:
Provider – sender is a transit provider to neighbor;
Customer – sender is a transit customer of neighbor;
RS – sender is a Route Server, usually at an Internet exchange point (IX);
RS-client – sender is client of an RS;
Peer – sender and neighbor are peers.
How are these roles configured?
If, for example, on a relationship in a BGP session between ASes, the local AS role is performed by the Provider, the remote AS role must be performed by the Customer and vice versa. Likewise, if the local AS role is performed by a Route Server (RS), the remote AS role must be performed by an RS-Client and vice versa. Local and remote AS roles can also be performed by two Peers (see table).
An example is included below.
BGP Capabilities
BGP capabilities are what the router advertises to its BGP peers to tell them which features it can support and, if possible, it will try to negotiate that capability with its neighbors. A BGP router determines the capabilities supported by its peer by examining the list of capabilities in the OPEN message. This is similar to a meeting between two multilingual individuals, one of whom speaks English, Spanish and Portuguese, while the other speaks French, Chinese and English. The common language between them is English, so they will communicate in that language. But they will not do so in French, as only one of them speaks this language. This is basically what has allowed BGP to grow so much with only a minor impact on our networks, as it incorporates these backward compatibility notions that work seamlessly.
This RFC has added a new capability.
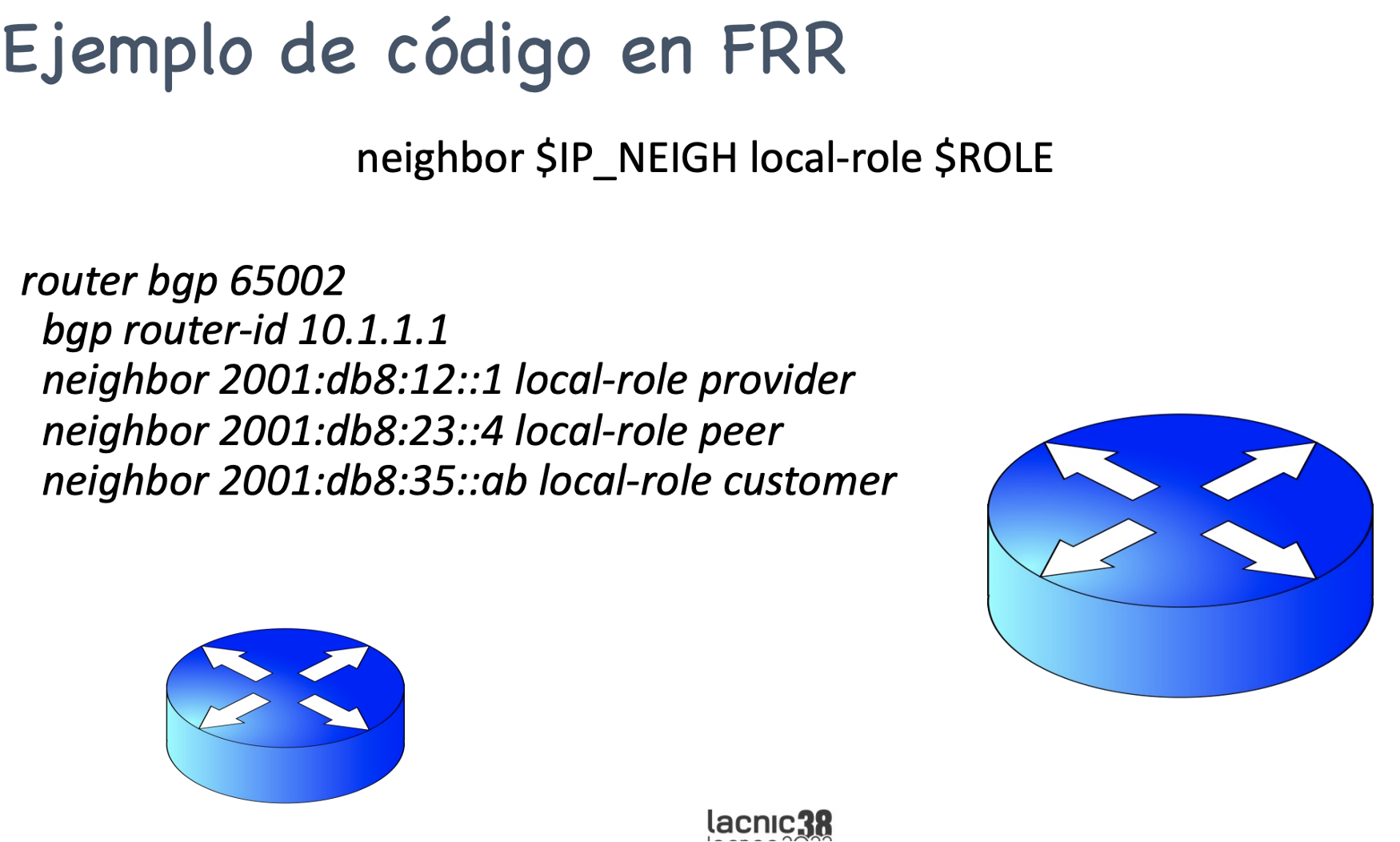
Does this code work? Absolutely. Here’s an example in FRR:
Strict Mode
Capabilities are generally negotiated between the BGP speakers, and only the capabilities supported by both speakers are used. If the Strict Mode option is configured, the two routers must support this capability.
In conclusion, I believe the way described in RFC 9234 will be the future of BGP configuration worldwide, replacing and greatly improving route leaks and improper Internet advertisements. It will make BGP configuration easier and serve as a complement to RPKI and IRR for reducing route leaks and allowing for cleaner routing tables.
Click here to watch the full presentation offered during LACNIC 38 LACNOG 2022.
https://news.lacnic.net/en/events/an-interesting-change-is-coming-to-bgp