Showing posts with label internet. Show all posts
Showing posts with label internet. Show all posts
Saturday, July 5, 2025
Tuesday, June 10, 2025
7 Challenges IPv6 Faced and How They Were Overcome
Did you ever think IPv6 wouldn’t really catch on? If so, this post is for you.
Over the past 20 years, IPv6 has faced multiple obstacles that have led many to question its future. From the outset, it encountered serious technical challenges: it wasn’t compatible with IPv4, many older devices didn’t support it, and as is often the case, there was considerable resistance from operators and companies. On top of that, several myths—like IPv6 was too complex or less secure—also worked against it.
But time and technology did their thing. Thanks to transition mechanisms, better routing practices, and the development of more advanced hardware, IPv6 proved not only that it could scale (we’re talking about 340 undecillion available addresses!), but also that it’s more efficient and secure than the old IPv4 protocol.
Today, IPv6 is no longer a promise: it’s a reality. It powers 5G, the future 6G, the large-scale Internet of Things, and the hyperconnected cloud. And it also solves problems we’ve been struggling with for years, such as address exhaustion and network fragmentation.
In this article, we’ll debunk some of the most common myths—like the idea that IPv6 slows down performance or doesn’t work well with legacy systems—and show, through data and real-world examples, why migrating to IPv6 is not only possible, but necessary if you want your network to be ready for the future.
1. Improved Packet Switching at the Hardware Level
Over the last 15 years, application-specific integrated circuits (ASICs) for networks have evolved from limited support to native and optimized IPv6 implementation. Before 2010, IPv6 processing relied on general-purpose CPUs, which led to high latency and low performance. Between 2010 and 2015, manufacturers such as Cisco and Broadcom integrated hardware-based IPv6 forwarding tables (TCAM), NDP/ICMPv6 support, and efficient lookup in chips such as the Cisco Nexus 7000 and Broadcom StrataXGS. By 2015-2020, ASICs had matured with scalable routing tables, IPv6 extension offloading (headers, tunneling), and integration with SDN/NFV, exemplified by Broadcom Tomahawk and Cisco Silicon One.
Since 2020, ASIC design has prioritized IPv6, introducing advanced capabilities such as accelerated IPv6 Segment Routing (SRv6), native security (hardware-based IPsec), and optimization for IoT/5G. Chips like Broadcom Jericho 2 (2020), Marvell Octeon 10 (2022), and Intel Tofino 3 (2023) support millions of IPv6 routes and programmable processing (P4), cementing IPv6 as the standard in modern networks. This evolution reflects the transition of IPv6 from a software add-on to a critical network hardware component.
Timeline IPv6 Support in ASICs Limitations
Pre-2010 Minimal or software-based High CPU cost, low efficiency
2010-2015 First implementations in TCAMs/ASICs Limited IPv6 tables
2015-2020 Maturity in enterprise routers/switches
2020-Today Native IPv6, optimized for cloud/5G/SRv6
Summary Comparison of ASIC Evolution
2. The Chicken-and-Egg Dilemma in IPv6
In the context of IPv6, the chicken-and-egg dilemma refers to the problem of promoting adoption of this new version of the Internet Protocol. It’s like launching a new type of phone that no one buys because there are no apps for it, while developers don’t build these apps because there aren’t enough users.
On the one hand, content providers (such as streaming platforms and websites) need enough IPv6 users to justify investing in infrastructure and optimization for the protocol. On the other, end users need access to content over IPv6 to feel motivated to transition away from IPv4. Without a solid commitment from both sides, a vicious cycle is created: the lack of users limits available content, and the lack of content discourages users from adopting IPv6.
In 2025, the situation is quite different: many of the world’s leading Content Delivery Networks (CDNs) and websites have supported IPv6 for years. As a result, customers who haven’t yet deployed IPv6 often experience slightly lower connectivity compared to those who have.
A driver of IPv6 adoption among providers is the impact of the gaming industry and its community. It is a well-known fact that major gaming consoles such as Xbox (since 2013) and PlayStation (since 2020) have broadly supported IPv6.
CDN/Website Year of IPv6 Adoption
Cloudflare 2011 First CDN to support IPv6 globally
Google (Search, YouTube) 2012 Gradual rollout
Facebook/Instagram 2013 Full adoption in 2014
Wikipedia 2013 One of the first sites to adopt IPv6
Akamai 2014 Gradual support by region
Netflix 2015 Prioritizes IPv6 to reduce latency
Amazon CloudFront 2016 Full support in edge locations
Apple (App Store) 2016 Mandatory requirement for iOS apps
Microsoft Azure CDN 2017
Fastly 2018 Native support in their entire network
IPv6 Content Adoption Table. Source: DeepSeek (May 2025)
3. Prefix Delegation Routing
Something very interesting happened 10-15 years ago: many Internet Service Providers (ISPs) faced multiple issues when implementing DHCPv6-PD (Prefix Delegation). Routing issues were often encountered. For example, a host or remote network (CPE) would successfully receive an IPv6 prefix, but the routes needed to reach that prefix were not configured at the ISP. It was as if the mailman knew your address but didn’t have a map to find his way to your home.
Today, ISPs have upgraded their infrastructure to automatically handle prefix delegation routing, while modern routers—both residential and enterprise—include robust support for DHCPv6-PD. Now, when a client receives an IPv6 block, the ISP immediately propagates the necessary routes, and the local router automatically configures the internal subnets. This has made IPv6 prefix delegation as reliable as traditional IPv4 DHCP, eliminating one of the early pain points of the transition.
Aspect 10 years ago Today (2024)
Prefix assignment DHCPv6-PD without core routing DHCPv6-PD + BGP/IGP auto advertisement
CPE behavior Received the prefix or didn’t configure routes Automatically configures LAN + routes
Connectivity Outbound traffic only (inbound traffic was lost) Fully bidirectional (inbound/outbound)
Workarounds NAT66, manually configured tunnels, redistribute connected on CPE Native routing with no workarounds
Comparison: 2014 vs. 2024
4. Training and Collective Learning
Two decades ago, adopting IPv6 represented both a technical and an educational challenge. Documentation was scarce, scattered, and often overly technical, which meant that many network administrators had to learn by trial and error. Early courses focused mainly on theoretical protocol specifications, providing little practical guidance for actual implementation in operational networks. This lack of quality training resources initially slowed IPv6 adoption, particularly in enterprise environments and small operators.
Today, various organizations, including LACNIC, have made a massive effort to educate and thus reduce the entry barriers for IPv6. Examples include the LACNIC Campus, which offers courses on IPv6 ranging from basic to advanced levels, along with blog posts, videos, podcasts, and other educational materials.
Initiatives like LACNOG (and other regional NOGs) as well as LACNIC’s now-classic hands-on IPv6 workshops have also contributed to creating spaces for training and technical discussions on IPv6 implementation in real-world networks.
In addition, many private companies have included IPv6 as a mandatory topic in their training and certification programs, covering it in both coursework and exams.
The technical community has also played its part: hundreds of individuals, from students to senior network engineers, regularly share resources on social media platforms, producing articles, videos, blog posts, and technical notes that help close knowledge gaps and strengthen collective learning around IPv6.
5. Application Support
Twenty years ago, IPv6 support in applications was a bit of a lottery. If both IPv4 and IPv6 were present on the network, things got even more complicated. For instance, on an IPv6-only network, any application using IPv4 addresses would inevitably fail. Many developers assumed that IPv4 would be available in all networks. Operating systems also had outdated libraries that didn’t support the new protocol. This created an absurd situation: even when a user or organization had a perfectly configured IPv6 network, their everyday tools—such as their email clients—would simply stop working.
Today, the situation has changed dramatically. Major platforms such as Apple’s App Store (since 2016) and Google Play now require new apps to be IPv6-compatible (although the latter doesn’t explicitly state this). At the same time, mechanisms such as Happy Eyeballs support the transition to IPv6 at the software level in a transparent manner. Major programming libraries (such as Python, Java, and Node.js) have included native support for IPv6 for years, eliminating excuses for developers. Companies like Microsoft, Google, and Cloudflare have led this change, demonstrating that IPv6 can outperform IPv4. What was once a challenge has become a competitive advantage: applications that are early adopters of IPv6 benefit from lower latency, better security, and access to the next generation of connected users.
6. Fragmentation and MTU (Maximum Transmission Unit)
Unlike IPv4, IPv6 eliminates fragmentation at intermediate routers. This means that packets must adhere to the MTU (Maximum Transmission Unit) across the entire path from source to destination. While this design decision improves overall network efficiency, in the early years of IPv6 deployment (10, 15, or 20 years ago), it caused quite a few headaches: many devices implemented the Path MTU Discovery (PMTUD) mechanism incorrectly, resulting in loss of connectivity in certain common situations.
Specifically, older routers and unpatched operating systems were unable to properly handle ICMPv6 “Packet Too Big” messages, which are essential for the sender to adjust the size of the packets. As a result, communication broke down on networks where the MTU was lower than expected.
Today, modern operating systems and network equipment handle PMTUD correctly, responding to and dynamically adjusting packet size based on ICMPv6 messages. Thanks to these improvements, these issues are much less common, and networks run with greater stability and efficiency under IPv6.
7. DNS Forwarding via RA
In the early years of IPv6 (up until around 2010), configuring DNS servers on network clients was a more complex and indirect process than it is today. Routers sent Router Advertisement (RA) messages with the O (Other Configuration) flag set, forcing clients to make an additional request via DHCPv6 to obtain DNS server information. Inherited from the IPv4 world, this approach had several drawbacks: higher configuration latency, dependency on an additional service, and greater complexity for simple networks or devices with limited resources, such as many IoT endpoints.
This limitation was addressed with the introduction of the RDNSS (Recursive DNS Server) option in ICMPv6 RA messages, formalized in RFC 6106 (2010). From then on, routers could directly advertise DNS servers to clients, drastically simplifying the autoconfiguration process.
Although initially met with some resistance from operating system and router vendors, support for RDNSS became popular between 2015 and 2017: Windows 10, Linux (with systemd-networkd), iOS 9+, and most enterprise routers had already implemented it.
Today, this functionality is almost universally available on modern devices and is considered a best practice in IPv6 networks, eliminating the need to use DHCPv6 only for DNS and enabling much simpler plug-and-play deployments.
Conclusions
In retrospect, after more than two decades of evolution, IPv6 has overcome obstacles that once seemed insurmountable, transforming from a largely theoretical protocol into the backbone of the modern Internet.
As a result of collaboration between the industry and organizations such as the IETF, standardized, efficient, and widely adopted solutions have now been found for the technical challenges that once created uncertainty. Myths such as its alleged “complexity” or “incompatibility” have been dispelled by concrete evidence of improved performance, greater security, and true scalability.
IPv6 is the present. With nearly 50% of global traffic now running over IPv6 (and almost 40% in Latin America and the Caribbean), native support across CDNs, operating systems, and applications, and a key role in technologies such as 5G, IoT, and hyperconnected cloud, full transition is only a matter of time. Continuing to delay IPv6 adoption doesn’t only mean missing out on technical advantages: it means moving towards obsolescence.
The lesson is clear: IPv6 adoption is a strategic imperative. Failing to implement IPv6 means risking isolation from an Internet that has already taken the next step.
References:
RFC 6106: https://datatracker.ietf.org/doc/html/rfc6106
LACNIC Statistics: https://stats.labs.lacnic.net/IPv6/graph-access.html
https://developer.apple.com/support/downloads/terms/app-review-guidelines/App-Review-Guidelines-20250430-English-UK.pdf
Wednesday, February 12, 2025
The History behind Netmasks.
Introduction
Do you remember when you were learning about netmasks? You probably thought that they were useless, that you wouldn’t need them, and wondered why they had invented something so insane. In addition to putting a smile on your face, I hope to convince you of their importance within the gigantic Internet ecosystem.
Goal
This blog post summarizes the history and milestones behind the concept of netmasks in the world of IPv4. This story begins in a world where classes didn’t exist (flat addressing), it then goes through a classful era and concludes with a totally classless Internet (CIDR). The information is based on excerpts from RFCs 790, 1338, and 1519, as well as on ‘Internet-history’ mailing list threads.
Do you know what a netmask is?
If you’re reading this document, I assume you do :-) but here’s a mini explanation: a netmask is used to identify and divide an IP address into a network address and a host address, in other words, it specifies the subnet partitioning system.
What is the purpose of netmasks?
Routing: Netmasks are used by routers to determine the network part of an IP address and route packets correctly.
Subnetting: Netmasks are used to create smaller networks.
Aggregation: Netmasks allow creating larger prefixes.
Have netmasks always existed?
Interestingly, netmasks haven’t always existed. In the beginning, IP networks were flat, and it was always assumed 8 bits were used for the network and 24 bits for the host. In other words, the first octet represented the network, while the remaining three octets corresponded to the host. It is also worth noting that many years ago, they were also referred to as bitmasks or simply masks — the latter term is still widely used today.
This means that classes (A, B, C, D) have not always existed
Classes were not introduced until Jon Postel’s RFC was published (September 1981), in other words, there was a time before classless and classful addressing. The introduction of the classful system was driven by the need to accommodate networks of different sizes, as the original 8-bit network ID was insufficient (256 networks). While the classful system attempted to address the limitations of a flat address space, it also faced scalability limitations. In the classful world, the netmask was implicit.
Classes did not solve every issue
Although the classful system represented an improvement over the original (flat) design, it was not efficient. The fixed size of the network and host portions of IP addresses led to exhaustion of the IP address space, particularly with the growing number of networks larger than a Class C but smaller than a Class B. This resulted in the development of Classless Interdomain Routing (CIDR), which uses Variable Length Subnet Masks (VLSM).

Excerpt from RFC 790
Did you know that netmasks were not always written with contiguous bits “on” from left to right?
In the beginning, netmasks didn’t have to be “lit” or “turned on” bit by bit from left to right. This means that masks such as 255.255.192.128 were entirely valid. This configuration was accepted by routers (IMPs, the first routers) and various operating systems, including BSDs and SunOSs. In other words, until the early 1990s, it was still possible for netmasks to have non-contiguous bits.
Why was it decided that it would be mandatory for bits to be turned on from left to right?
There were several reasons for this decision, the main one relating to routing and the well-known concept of “longest match” where routers select the route with the longest subnet mask that matches the packet’s destination address. If the bits are not contiguous, the computational complexity is very high. In short, efficiency.
Back then, IPv4 exhaustion was already underway
IPv4 resource exhaustion is not a recent phenomenon. In fact, item #1 of the first section of RFC 1338 mentions the exhaustion of Class B network address space, noting that Class C is too small for many organizations, and Class B is too large to be widely allocated. This led to pressure on the Class B address space, which was exhausted. Furthermore, item #3 of the same RFC mentions the “Eventual exhaustion of the 32-bit IP address space” (1992).
CIDR tackles the solutions of the past, which later became the problems of the time
The creation of classes led to the creation of more networks, which meant an increase in prefixes and consequently a higher consumption of memory and CPU. Thus, in September 1993, RFC 1519 introduced the concept of CIDR, which brought with it solutions to different challenges, including the ability to perform supernetting (i.e., being able to turn off bits from right to left) and attempting to reduce the number of network prefixes. It should be noted that RFC 1338 also maintained similar concepts.
Finally, prefix notation (/nn) also appeared thanks to CIDR and was possible because the “on” and “off” bits of the netmask were contiguous.
In summary, the primary goals of CIDR were to slow the growth of routing tables and improve efficiency in the use of IP address space.

Timeline
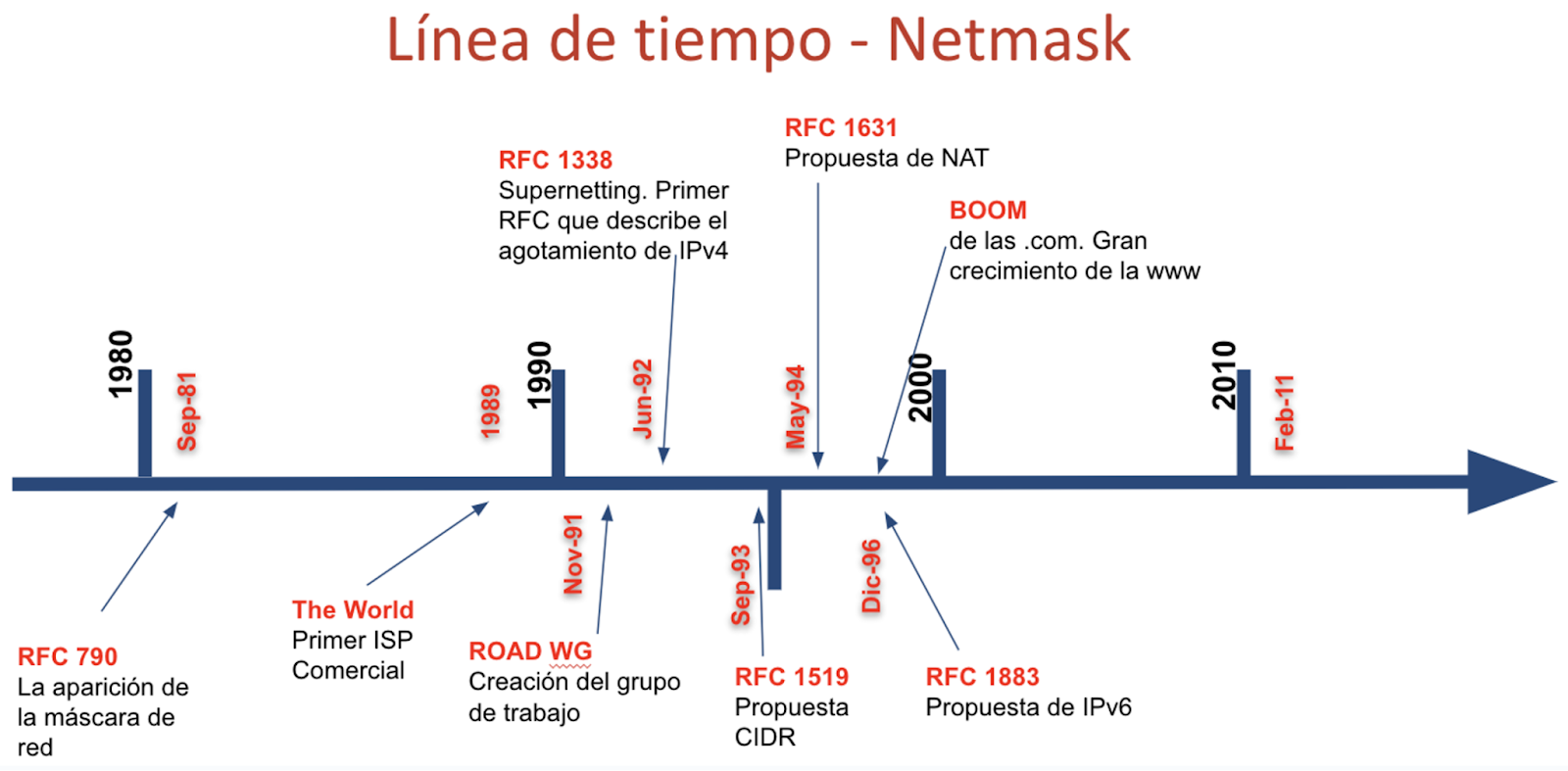
Conclusions
The concept of the netmask has evolved significantly since its origin, from not existing in a flat addressing scheme, to a rigid and then to a flexible model with CIDR. Initially, classful networks and non-contiguous masks created inefficiency and scalability issues as the Internet expanded.
A key change was the requirement of contiguous “on” bits, as this simplified the route selection process and allowed routers to operate more efficiently.
This document highlights the key milestones and motivations behind the evolution of IP addressing and underscores the importance of understanding the historical context to fully appreciate the Internet’s current architecture.
References
RFC https://datatracker.ietf.org/doc/html/rfc1338
RFC https://datatracker.ietf.org/doc/html/rfc1380
RFC https://datatracker.ietf.org/doc/html/rfc1519
RFC https://datatracker.ietf.org/doc/html/rfc790
ISOC “Internet History” mailing list, thread with the subject “The netmask”: https://elists.isoc.org/pipermail/internet-history/2025-January/010060.html
Thursday, June 29, 2023
Thursday, December 1, 2022
An Interesting Change Is Coming to BGP
A route leak is defined as the propagation of routing announcement(s) beyond their intended scope (RFC 7908). But why do route leaks occur? The reasons are varied and include errors (typos when entering a number), ignorance, lack of filters, social engineering, and others.
Although there are several ways to prevent route leaks and, in fact, their number has decreased over the past three years (thanks to RPKI, IRR, and other mechanisms), I will try to explain what I believe BGP configurations will look like in the future. To do so, I will talk about RFC 9234, Route Leak Prevention and Detection Using Roles in UPDATE and OPEN Messages. And the part I would like to highlight is “role detection” as, after this RFC, in the future, we will assign roles in our BGP configurations.
To understand what we want to achieve, let’s recall some typical situations for an ISP:
a new customer comes along with whom we will speak BGP,
a connection to an IXP,
the ISP buys capacity from a new upstream provider,
a new private peering agreement.
In all these cases decisions need to be made. There are multiple ways to configure BGP, including route maps, AS filters, prefix lists, communities, ACLS, and others. We may even be using more than one of these options.
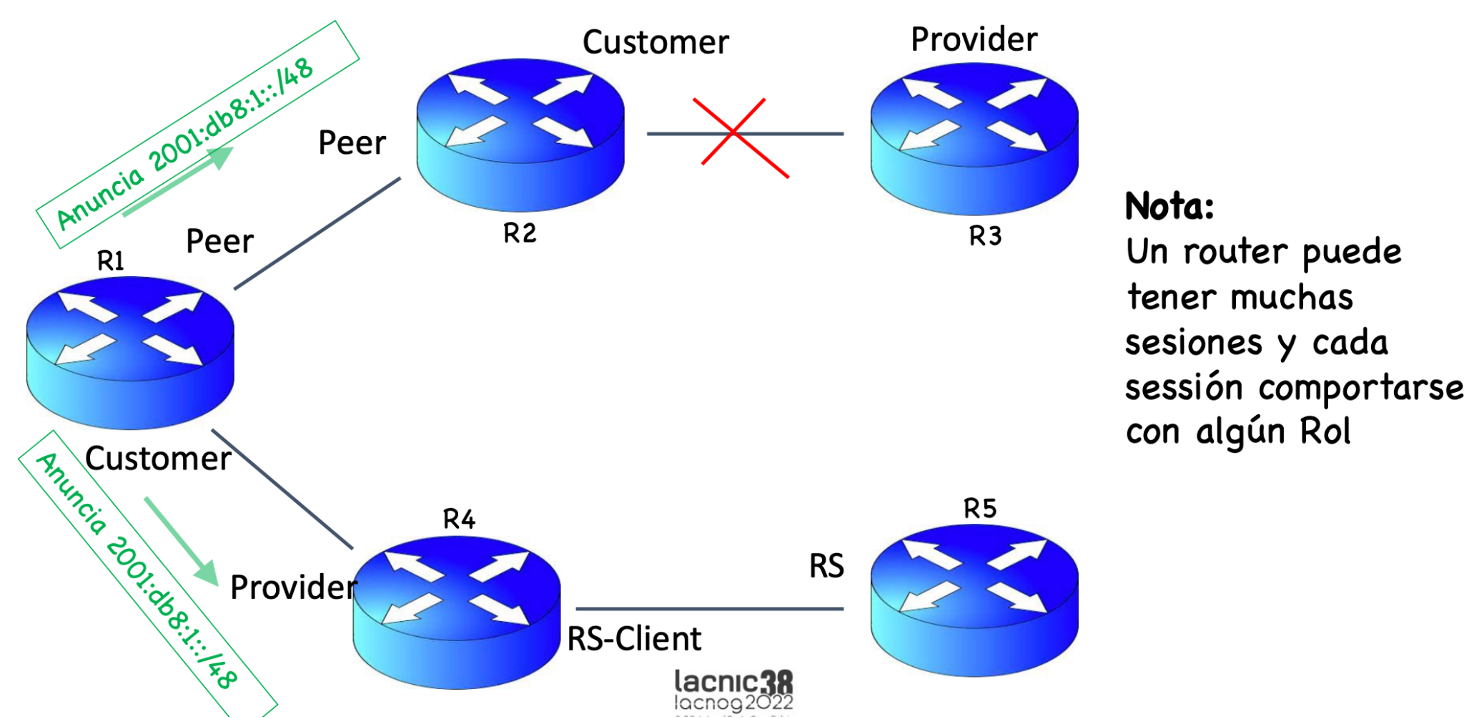
This is where RFC 9324 enters the picture: the document establishes the roles in the BGP OPEN message, i.e., it establishes an agreement of the relationship on each BGP session between autonomous systems. For example, let’s say that I am a router and I speak to another router and tell them that I am a “customer”; in turn, the other router’s BGP session can say “I am your provider.” Based on this exchange, all configurations (i.e., filters) will be automatic, which should help reduce route leaks.
These capabilities are then negotiated in the BGP OPEN message.
The RFC defines five roles:
Provider – sender is a transit provider to neighbor;
Customer – sender is a transit customer of neighbor;
RS – sender is a Route Server, usually at an Internet exchange point (IX);
RS-client – sender is client of an RS;
Peer – sender and neighbor are peers.
How are these roles configured?
If, for example, on a relationship in a BGP session between ASes, the local AS role is performed by the Provider, the remote AS role must be performed by the Customer and vice versa. Likewise, if the local AS role is performed by a Route Server (RS), the remote AS role must be performed by an RS-Client and vice versa. Local and remote AS roles can also be performed by two Peers (see table).

An example is included below.
BGP Capabilities
BGP capabilities are what the router advertises to its BGP peers to tell them which features it can support and, if possible, it will try to negotiate that capability with its neighbors. A BGP router determines the capabilities supported by its peer by examining the list of capabilities in the OPEN message. This is similar to a meeting between two multilingual individuals, one of whom speaks English, Spanish and Portuguese, while the other speaks French, Chinese and English. The common language between them is English, so they will communicate in that language. But they will not do so in French, as only one of them speaks this language. This is basically what has allowed BGP to grow so much with only a minor impact on our networks, as it incorporates these backward compatibility notions that work seamlessly.
This RFC has added a new capability.

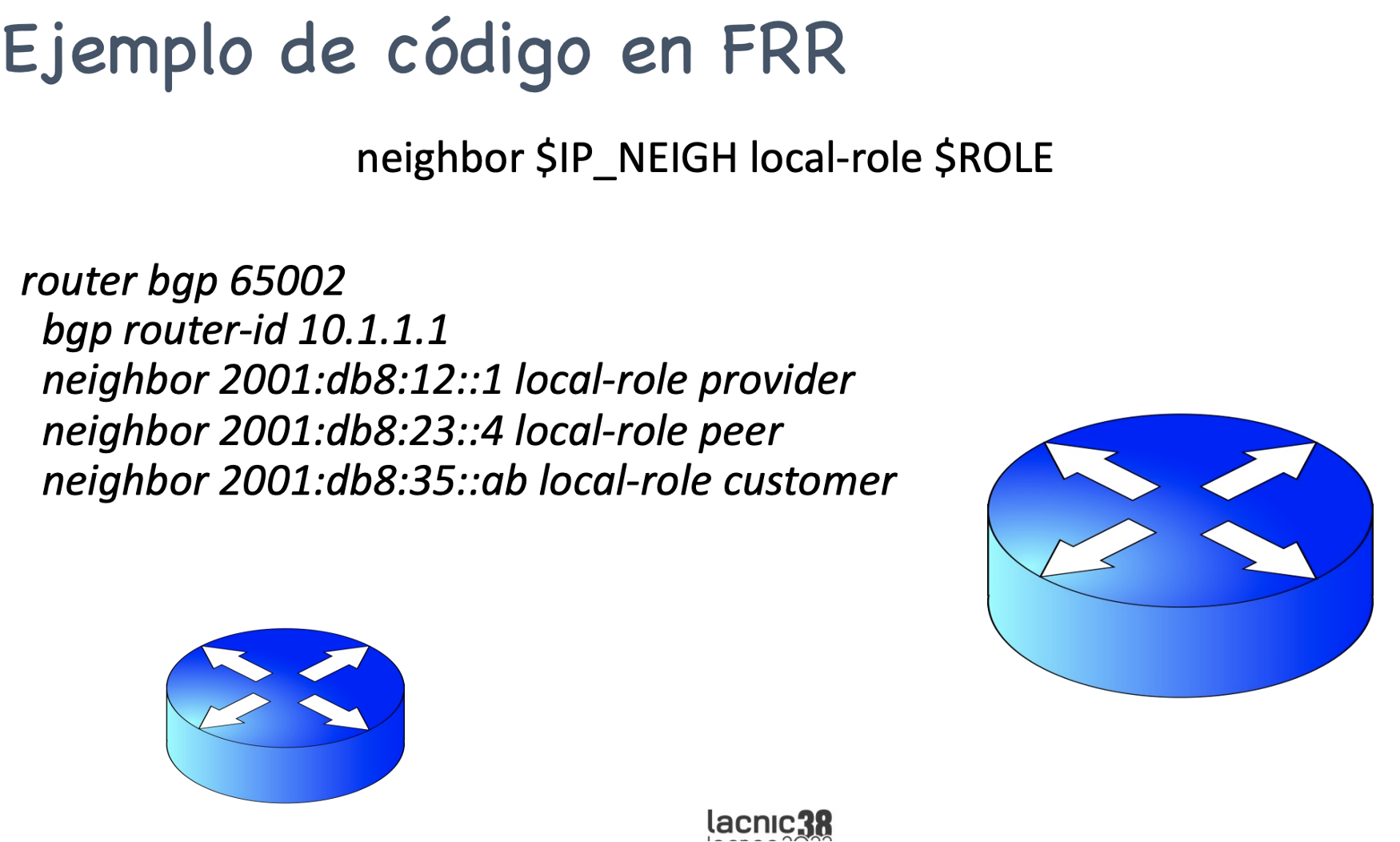
Does this code work? Absolutely. Here’s an example in FRR:
Strict Mode
Capabilities are generally negotiated between the BGP speakers, and only the capabilities supported by both speakers are used. If the Strict Mode option is configured, the two routers must support this capability.
In conclusion, I believe the way described in RFC 9234 will be the future of BGP configuration worldwide, replacing and greatly improving route leaks and improper Internet advertisements. It will make BGP configuration easier and serve as a complement to RPKI and IRR for reducing route leaks and allowing for cleaner routing tables.
Click here to watch the full presentation offered during LACNIC 38 LACNOG 2022.
https://news.lacnic.net/en/events/an-interesting-change-is-coming-to-bgp
Thursday, February 24, 2022
Why Is IPv6 So Important for the Development of the Metaverse?
By Gabriel E. Levy B. and Alejandro Acosta
Over almost half a century, the TCP/IP protocols have helped connect billions of people.
Since the creation of the Internet, they have been the universal standards used to transmit information, making it possible for the Internet to function[3].
The acronym ‘IP’ can refer to two different but interrelated concepts. The first is a protocol (the Internet Protocol) whose main function is to be used in bidirectional (source and destination) data transmission based on the Open System Interconnection (OSI) standard[4]. The second possible reference when talking about IP involves the assignment of physical addresses in the form of numbers known as ‘IP Addresses’. An IP address is a logical and hierarchical identifier assigned to a network device that uses the Internet Protocol (IP). It corresponds to the network layer, or layer 3 of the OSI model.
IPv4 refers to the fourth version of the Internet Protocol, a standard for the interconnection of Internet-based networks which was implemented in 1983 for the operation of ARPANET and its subsequent migration to the Internet.[5].
IPv4 uses 32-bit addresses, the equivalent of 4.3 billion unique numbering blocks, a figure that back in the 80s appeared to be inexhaustible. However, thanks to the enormous and unforeseen growth of the Internet, by 2011 the unexpected had happened: IPv4 addresses had been exhausted[6].
IPv6 as a solution to the bottleneck
To address the lack of available address resources, the engineering groups responsible for the Internet have resorted to multiple solutions, ranging from the creation of private subnets so that multiple users can connect using a single address, to the creation of a new protocol called IPv6 which promises to be the definitive solution to the problem and which was officially launched on 6 June 2012[7]:
“Anticipating IPv4 address exhaustion and seeking to provide a long-term solution to the problem, the organization that promotes and develops Internet standards (the Internet Engineering Task Force or IETF) designed a new version of the Internet Protocol, specifically version 6 (IPv6), with provides almost limitless availability based on a the use of 128-bit addresses, the equivalent to approximately 340 undecillion addresses”**[[8]**.
It should be noted, however, that the creation of the IPv6 protocol did not anticipate a migration or shift from one protocol to another. Instead, a mechanism was designed to allow both protocols to coexist for a time.
To ensure that the transition would be transparent to users and to allow a reasonable amount of time for vendors to incorporate the new technology and for Internet providers to implement the new version of the protocol in their own networks, along with the IPV6 protocol itself, the organization responsible for Internet protocol standardization — the IETF — designed a series of transition and coexistence mechanisms.
“Imagine this is a weight scale where the plate carrying the heaviest weight currently represents IPv4 traffic. However, little by little and thanks to this coexistence, as more content and services become available over IPv6, the weight of the scale will shift to the other plate, until IPv6 traffic outweighs IPv4. This is what we call the transition”**[9]**.
If both protocols (IPv4 and IPv6) are available, IPv6 is preferred by design. This is why the balance shifts naturally, depending on multiple factors and without us being able to determine how long IPv4 will continue to exist and in what proportion. If one had a crystal ball, one might say that IPv6 will become the dominant protocol in three or four years, and that IPv4 will disappear from the Internet — or at least from many parts of the Internet — in the same timeframe”[10].
Without IPv6 there may be no Metaverse
Metaverses or metauniverses are environments where humans interact socially and economically through their avatars in cyberspace, which is an amplified metaphor for the real world, except that there are no physical or economic limitations[11].
“You can think about the Metaverse as an embodied Internet, where instead of just viewing content — you are in it. And you feel present with other people as if you were in other places, having different experiences that you couldn’t necessarily have on a 2D app or webpage.” Mark Zuckerberg, Facebook CEO**[12]**.
The Metaverse necessarily runs on the Internet, which in turn uses the Internet Protocol (IP) to function.
The Metaverse is a type of simulation where avatars allow users to have much more immersive and realistic connections by displaying a virtual universe that runs online. This is why it is necessary to ensure that the Metaverse is immersive, multisensory, interactive, that it runs in real time, that it allows each user to be precisely differentiated, and that it deploys simultaneous and complex graphic tools, among many other elements. All this would be impossible to guarantee with the IPv4 protocol, as the number of IP addresses would not be enough to cover each connection, nor would it be possible to guarantee that technologies such as NAT would function properly.
Key elements:
- IPv6 is the only protocol that can guarantee enough IP resources to support the Metaverse.
- IPv6 avoids the use of NAT mechanisms that would create technological difficulties for the deployment of the Metaverse.
- IPv6 links have lower RTT delay than IPv4 links, and this allows avatar representations, including holograms, to be displayed synchronously.
- Considering the huge amount of data involved in the deployment of the Metaverse, it is necessary to ensure the least possible data loss. This is why IPv6 is the best option, as evidence shows that data loss is 20% lower when using IPv6 than when using IPv4[13].
The role of small ISPs
Considering that small ISPs are responsible for the connectivity of millions of people across Latin America and that, as previously noted, they are largely responsible for reducing the digital divide[14], it is very It is important for these operators to accelerate their migration/transition to IPv6, not only to remain competitive in relation to larger operators, but also to be able to guarantee their users that technologies such as the Metaverse will work on their devices without major technological headaches.
In conclusion, while the true scope of the Metaverse remains to be seen, its deployment, implementation, and widespread adoption will be possible thanks to the IPv6 protocol, a technology that has provided a solution to the availability of IP resources, avoiding the cumbersome network address translation (NAT) process, improving response times, reducing RTT delay, and decreasing packet losses, while at the same time allowing simultaneous utilization by an enormous number of users.
All of the above leads us to conclude that the Metaverse would not be possible without IPv6.
Disclaimer: This article contains a review and analysis undertaken in the context of the digital transformation within the information society and is duly supported by reliable and verified academic and/or journalistic sources, which have been delimited and published.
The information contained in this journalistic and opinion piece does not necessarily represent the position of Andinalink or of the organizations commercially related with Andinalink.
[1] Andinalink article: Metaversos y el Internet del Futuro (Metaverses and the Internet of the Future)
[2] Andinalink article: Metaversos: Expectativas VS Realidad (Metaverses: Expectations vs Reality)
[3] In the article titled: El agotamiento del protocolo IP (The Exhaustion of the IP Protocol) we explain the characteristics of the TCP protocol.
[4] Standard reference document on the OSI connectivity model
[5] The article titled: ¿Fue creada Arpanet para soportar una guerra nuclear? (Was Arpanet Created to Withstand a Nuclear War?) details the features and history of Arpanet.
[6] LACNIC document on the Phases of IPv4 Exhaustion
[7] Document published by the IETF about World IPv6 Launch on its sixth anniversary
[8] Guide for the Transition to IPv6 published by the Colombian Ministry of Information and Communications Technology
[9] Guide for the Transition to IPv6 published by the Colombian Ministry of Information and Communications Technology
[10] Guide for the Transition to IPv6 published by the Colombian Ministry of Information and Communications Technology
[11] Andinalink article on Metaverses
[12] Mark in the Metaverse: Facebook’s CEO on why the social network is becoming ‘a metaverse company: The Verge Podcast
[13] Analysis by Alejandro Acosta (LACNIC) of the impact of IPv6 on tactile systems
[14] Andinalink article: Los WISP disminuyen la brecha digital (WISPs Reduce the Digital Divide)
Friday, June 25, 2021
IPv6 Deployment - LACNIC region
The video below shows the IPv6 deployment for the LACNIC region using a Bar Chart Race format
Made with https://flourish.studio/
Friday, September 6, 2019
The sad tale of the ISP that didn’t deploy IPv6
Once upon a time in the not so distant past, a large ISP dominated a country’s
telecommunications market and felt powerful and without competition. Whenever someone
needed to log on to the
Internet they would use their services. Everyone envied their market penetration.
This large ISP, however, had never wanted to deploy IPv6 because they thought their stock
of IP addresses was enough and saw no indicator telling them that they needed the new
protocol.
During the course of those years, another smaller ISP began implementing IPv6 and slowly
began to grow, as they realized that the protocol did indeed make a difference in the eyes of their
clients and that it was helping them win over new users.
The small ISP’s market penetration continued to grow, as did their earnings and general respect
for their services. As they grew, it became easier for them to obtain better equipment, traffic
and interconnection prices. Everything was going very well. The small ISP couldn’t believe that
something as simple as deploying IPv6 could be paying off so spectacularly. Their customers
told them their needs included running VPNs and holding conference calls with partners in
other parts of the world, and that their subsidiaries, customers and business partners in Europe
and Asia had already adopted IPv6.
Despite being so powerful, the large ISP began experiencing internal problems that were
neither billing nor money related. Sales staff complained that they were having trouble closing
many deals because customers had started asking for IPv6 and, although their ISP was so
large and important, they simply did not have IPv6 to offer. Both corporate customers and
residential users were asking for IPv6; even major state tenders were requiring IPv6.
When this started happening, the Sales Manager complained to the Products, Engineering and
Operations departments. The latter were left speechless and some employees were let go by
the company. In the end, Sales did not care where the fault lay – they were simply unable to
gain new customers. Realizing that they were losing customers, some of the salespeople
accepted job offers at the small ISP who was looking to grow their staff as they could now
afford the best sales force.
Then the same thing happened with the larger ISP’s network manager, an expert who knew
a lot about IPv6 but who had been unable to overcome the company’s bureaucracy and bring
the new protocol into production. Logically, the network manager was followed by his trusted
server administrator and head of security. The large ISP couldn’t believe what was happening
right before their very eyes. The sales force hired by the smaller ISP (those who used to
work for the large ISP) brought with them their huge customer base, all of them potential prospects.
A stampede of the large ISP’s clients was on the way. The months went by and the smaller
ISP was no longer simply offering Internet access – its Data Center had grown, major
companies brought in new cache servers and much more. They were now offering co-location,
hosting, virtual hosting, voice and video, among many other services.
When the large provider decided to deploy IPv6, it had to do so very quickly. Things went
wrong; many errors were made. In addition, certain consultants and companies took
advantage of their problems and charged higher rush fees. Network downtime increased,
as did the number of calls to the call center. The large ISP’s reputation started to crumble.
As expected, in the end, everyone who was part of this story – clients and providers alike –
ended up deploying IPv6. Some ended up happier than others, but everyone adopted IPv6
on their networks.
By Alejandro Acosta
Thursday, August 24, 2017
Google DNS --- Figuring out which DNS Cluster you are using
(this is -almost- a copy / paste of an email sent by Erik Sundberg to nanog mailing list on
August 23).
This post is being posted with his explicit permission.
I sent this out on the outage list, with a lots of good feedback sent to me. So I figured it
I sent this out on the outage list, with a lots of good feedback sent to me. So I figured it
would be useful to share the information on nanog as well.
A couple months ago had to
troubleshoot a google DNS issue with Google’s NOC. Below is some helpful information
on how to determine which DNS Cluster you are going to.
Let’s remember that Google runs
DNS Anycast for DNS queries to 8.8.8.8 and 8.8.4.4. Anycast routes your DNS queries to
the closes DNS cluster based on the best route / lowest metric to 8.8.8.8/8.8.4.4. Google
has deployed multiple DNS clusters across the world and each DNS Cluster has multiple
servers.
So a DNS query in Chicago will go to a different DNS clusters than queries from
a device in Atlanta or New York.
How to get a list of google DNS Cluster’s. dig -t TXT +short locations.publicdns.goog. @8.8.8.8 How to print this list in a table format.
-- Script from: https://developers.google.com/speed/public-dns/faq --
#!/bin/bash
IFS="\"$IFS"
for LOC in $(dig -t TXT +short locations.publicdns.goog. @8.8.8.8)
do
case $LOC in
'') : ;;
*.*|*:*) printf '%s ' ${LOC} ;;
*) printf '%s\n' ${LOC} ;;
esac
done
---------------
Which will give you a list like below. This is all of the IP network’s that
google uses for their DNS Clusters and their associated locations.
74.125.18.0/26 iad 74.125.18.64/26 iad 74.125.18.128/26 syd 74.125.18.192/26 lhr 74.125.19.0/24 mrn 74.125.41.0/24 tpe 74.125.42.0/24 atl 74.125.44.0/24 mrn 74.125.45.0/24 tul 74.125.46.0/24 lpp 74.125.47.0/24 bru 74.125.72.0/24 cbf 74.125.73.0/24 bru 74.125.74.0/24 lpp 74.125.75.0/24 chs 74.125.76.0/24 cbf 74.125.77.0/24 chs 74.125.79.0/24 lpp 74.125.80.0/24 dls 74.125.81.0/24 dub 74.125.92.0/24 mrn 74.125.93.0/24 cbf 74.125.112.0/24 lpp 74.125.113.0/24 cbf 74.125.115.0/24 tul 74.125.176.0/24 mrn 74.125.177.0/24 atl 74.125.179.0/24 cbf 74.125.181.0/24 bru 74.125.182.0/24 cbf 74.125.183.0/24 cbf 74.125.184.0/24 chs 74.125.186.0/24 dls 74.125.187.0/24 dls 74.125.190.0/24 sin 74.125.191.0/24 tul 172.217.32.0/26 lhr 172.217.32.64/26 lhr 172.217.32.128/26 sin 172.217.33.0/26 syd 172.217.33.64/26 syd 172.217.33.128/26 fra 172.217.33.192/26 fra 172.217.34.0/26 fra 172.217.34.64/26 bom 172.217.34.192/26 bom 172.217.35.0/24 gru 172.217.36.0/24 atl 172.217.37.0/24 gru 173.194.90.0/24 cbf 173.194.91.0/24 scl 173.194.93.0/24 tpe 173.194.94.0/24 cbf 173.194.95.0/24 tul 173.194.97.0/24 chs 173.194.98.0/24 lpp 173.194.99.0/24 tul 173.194.100.0/24 mrn 173.194.101.0/24 tul 173.194.102.0/24 atl 173.194.103.0/24 cbf 173.194.168.0/26 nrt 173.194.168.64/26 nrt 173.194.168.128/26 nrt 173.194.168.192/26 iad 173.194.169.0/24 grq 173.194.170.0/24 grq 173.194.171.0/24 tpe 2404:6800:4000::/48 bom 2404:6800:4003::/48 sin 2404:6800:4006::/48 syd 2404:6800:4008::/48 tpe 2404:6800:400b::/48 nrt 2607:f8b0:4001::/48 cbf 2607:f8b0:4002::/48 atl 2607:f8b0:4003::/48 tul 2607:f8b0:4004::/48 iad 2607:f8b0:400c::/48 chs 2607:f8b0:400d::/48 mrn 2607:f8b0:400e::/48 dls 2800:3f0:4001::/48 gru 2800:3f0:4003::/48 scl 2a00:1450:4001::/48 fra 2a00:1450:4009::/48 lhr 2a00:1450:400b::/48 dub 2a00:1450:400c::/48 bru 2a00:1450:4010::/48 lpp 2a00:1450:4013::/48 grq There are IPv4 Networks: 68 IPv6 Networks: 20 DNS Cluster’s Identified by POP Code’s: 20
DNS Clusters identified by POP Code to City, State, or Country. Not all
of these are Google’s Core Datacenters, some of them are Edge Points of Presences (POPs). https://peering.google.com/#/infrastructure and https://www.google.com/about/datacenters/inside/locations/
Most of these are airport codes, it did my best to get the location correct. iad Washington, DC syd Sydney, Australia lhr London, UK mrn Lenoir, NC tpe Taiwan atl Altanta, GA tul Tulsa, OK lpp Findland bru Brussels, Belgium cbf Council Bluffs, IA chs Charleston, SC dls The Dalles, Oregon dub Dublin, Ireland sin Singapore fra Frankfort, Germany bom Mumbai, India gru Sao Paulo, Brazil scl Santiago, Chile nrt Tokyo, Japan grq Groningen, Netherlans Which Google DNS Server Cluster am I using. I am testing this from Chicago,
IL # dig o-o.myaddr.l.google.com -t txt +short @8.8.8.8 "173.194.94.135"
<<<<<<DNS Server IP, reference the list above to get the cluster, Council
Bluffs, IA "edns0-client-subnet 207.xxx.xxx.0/24" <<<< Your Source IP Block Side note,
the google dns servers will not respond to DNS queries to the Cluster’s Member’s IP,
they will only respond to dns queries to 8.8.8.8 and 8.8.4.4. So the following will
not work.
dig google.com @173.194.94.135 Now to see the DNS Cluster load balancing
in action. I am doing a dig query from our Telx\Digital Realty POP in Atlanta, GA.
We do peer with google at this location. I dig a dig query about 10 times and received
the following unique dns cluster member ip’s as responses.
dig o-o.myaddr.l.google.com -t txt +short @8.8.8.8 "74.125.42.138" "173.194.102.132" "74.125.177.5" "74.125.177.74" "74.125.177.71" "74.125.177.4" Which all are Google DNS Networks in Atlanta. 74.125.42.0/24 atl 74.125.177.0/24 atl 172.217.36.0/24 atl 173.194.102.0/24 atl 2607:f8b0:4002::/48 atl Just thought it would be helpful when troubleshooting google DNS
issues.
(this is -almost- a copy / paste of an email sent by Erik Sundberg to nanog mailing list onAugust 23 2017).This post is being posted with his explicit permission.
Subscribe to:
Posts (Atom)