Introduction
Do you remember when you were learning about netmasks? You probably thought that they were useless, that you wouldn’t need them, and wondered why they had invented something so insane. In addition to putting a smile on your face, I hope to convince you of their importance within the gigantic Internet ecosystem.
Goal
This blog post summarizes the history and milestones behind the concept of netmasks in the world of IPv4. This story begins in a world where classes didn’t exist (flat addressing), it then goes through a classful era and concludes with a totally classless Internet (CIDR). The information is based on excerpts from RFCs 790, 1338, and 1519, as well as on ‘Internet-history’ mailing list threads.
Do you know what a netmask is?
If you’re reading this document, I assume you do :-) but here’s a mini explanation: a netmask is used to identify and divide an IP address into a network address and a host address, in other words, it specifies the subnet partitioning system.
What is the purpose of netmasks?
Routing: Netmasks are used by routers to determine the network part of an IP address and route packets correctly.
Subnetting: Netmasks are used to create smaller networks.
Aggregation: Netmasks allow creating larger prefixes.
Have netmasks always existed?
Interestingly, netmasks haven’t always existed. In the beginning, IP networks were flat, and it was always assumed 8 bits were used for the network and 24 bits for the host. In other words, the first octet represented the network, while the remaining three octets corresponded to the host. It is also worth noting that many years ago, they were also referred to as bitmasks or simply masks — the latter term is still widely used today.
This means that classes (A, B, C, D) have not always existed
Classes were not introduced until Jon Postel’s RFC was published (September 1981), in other words, there was a time before classless and classful addressing. The introduction of the classful system was driven by the need to accommodate networks of different sizes, as the original 8-bit network ID was insufficient (256 networks). While the classful system attempted to address the limitations of a flat address space, it also faced scalability limitations. In the classful world, the netmask was implicit.
Classes did not solve every issue
Although the classful system represented an improvement over the original (flat) design, it was not efficient. The fixed size of the network and host portions of IP addresses led to exhaustion of the IP address space, particularly with the growing number of networks larger than a Class C but smaller than a Class B. This resulted in the development of Classless Interdomain Routing (CIDR), which uses Variable Length Subnet Masks (VLSM).

Excerpt from RFC 790
Did you know that netmasks were not always written with contiguous bits “on” from left to right?
In the beginning, netmasks didn’t have to be “lit” or “turned on” bit by bit from left to right. This means that masks such as 255.255.192.128 were entirely valid. This configuration was accepted by routers (IMPs, the first routers) and various operating systems, including BSDs and SunOSs. In other words, until the early 1990s, it was still possible for netmasks to have non-contiguous bits.
Why was it decided that it would be mandatory for bits to be turned on from left to right?
There were several reasons for this decision, the main one relating to routing and the well-known concept of “longest match” where routers select the route with the longest subnet mask that matches the packet’s destination address. If the bits are not contiguous, the computational complexity is very high. In short, efficiency.
Back then, IPv4 exhaustion was already underway
IPv4 resource exhaustion is not a recent phenomenon. In fact, item #1 of the first section of RFC 1338 mentions the exhaustion of Class B network address space, noting that Class C is too small for many organizations, and Class B is too large to be widely allocated. This led to pressure on the Class B address space, which was exhausted. Furthermore, item #3 of the same RFC mentions the “Eventual exhaustion of the 32-bit IP address space” (1992).
CIDR tackles the solutions of the past, which later became the problems of the time
The creation of classes led to the creation of more networks, which meant an increase in prefixes and consequently a higher consumption of memory and CPU. Thus, in September 1993, RFC 1519 introduced the concept of CIDR, which brought with it solutions to different challenges, including the ability to perform supernetting (i.e., being able to turn off bits from right to left) and attempting to reduce the number of network prefixes. It should be noted that RFC 1338 also maintained similar concepts.
Finally, prefix notation (/nn) also appeared thanks to CIDR and was possible because the “on” and “off” bits of the netmask were contiguous.
In summary, the primary goals of CIDR were to slow the growth of routing tables and improve efficiency in the use of IP address space.

Timeline
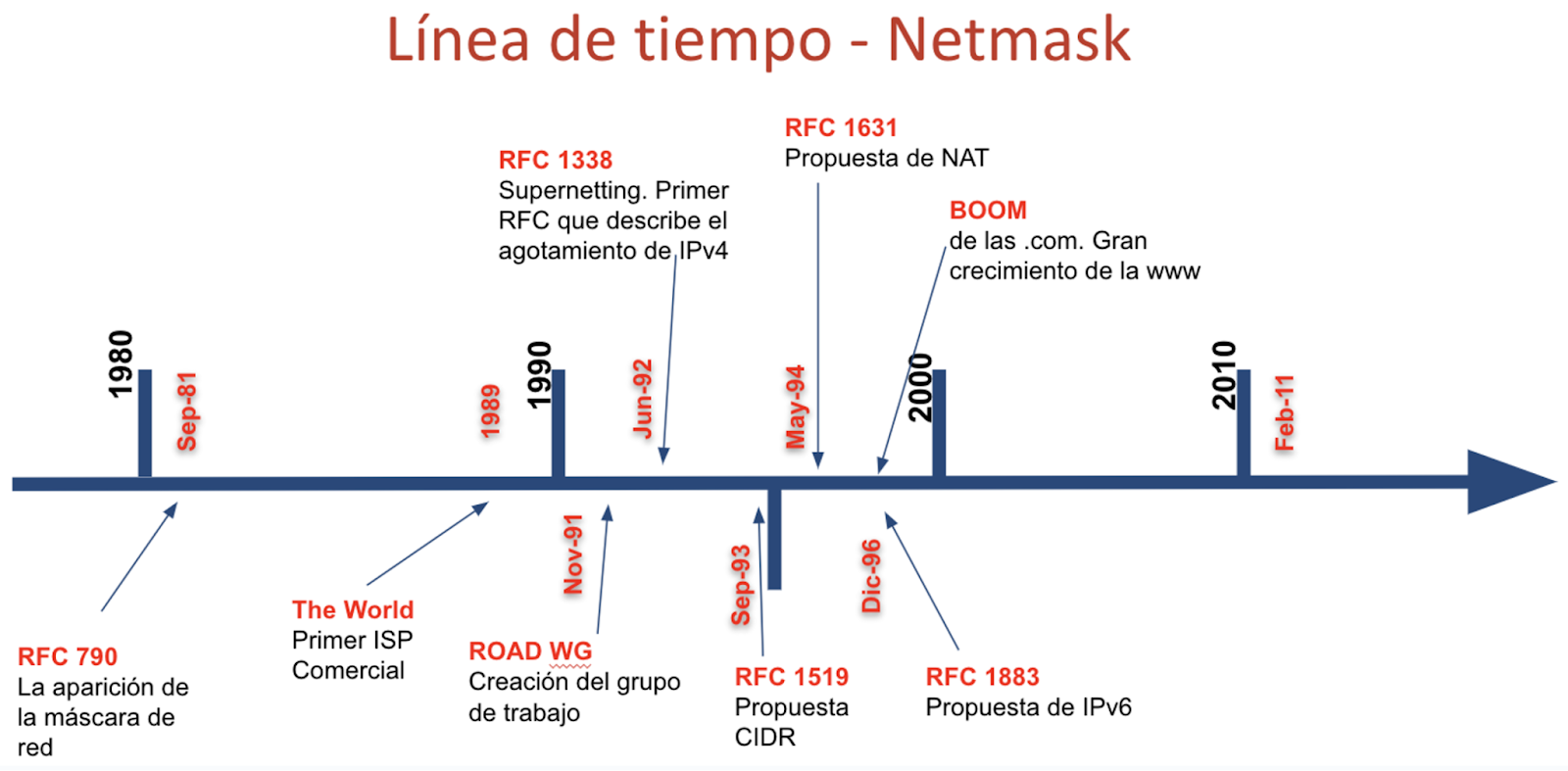
Conclusions
The concept of the netmask has evolved significantly since its origin, from not existing in a flat addressing scheme, to a rigid and then to a flexible model with CIDR. Initially, classful networks and non-contiguous masks created inefficiency and scalability issues as the Internet expanded.
A key change was the requirement of contiguous “on” bits, as this simplified the route selection process and allowed routers to operate more efficiently.
This document highlights the key milestones and motivations behind the evolution of IP addressing and underscores the importance of understanding the historical context to fully appreciate the Internet’s current architecture.
References
RFC https://datatracker.ietf.org/doc/html/rfc1338
RFC https://datatracker.ietf.org/doc/html/rfc1380
RFC https://datatracker.ietf.org/doc/html/rfc1519
RFC https://datatracker.ietf.org/doc/html/rfc790
ISOC “Internet History” mailing list, thread with the subject “The netmask”: https://elists.isoc.org/pipermail/internet-history/2025-January/010060.html